前言
经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo。这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程。
经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo。这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程。
2016年在重庆瓢虫的聚餐中开始,在成都瓢虫的年终聚餐中结尾。感谢瓢虫映像的大家给我这个独自在异乡漂泊的人带来了这么多的温暖,也感谢重庆和成都帮助我的同事和朋友,还有那些旅途上相遇的朋友感谢你们给我留下的美好回忆。
首先ctrl+alt+t打开终端,输入下列代码:
1 | sudo apt-get install phpmyadmin |
等待安装成功后,在终端继续输入下列代码:
1 | sudo ln -s /usr/share/phpmyadmin/ /var/www/html |
这是因为系统在安装软件时,默认将软件安装在了/usr/share/下,我们需要将phpmyadmin文件夹和/var/www/html建立联系。
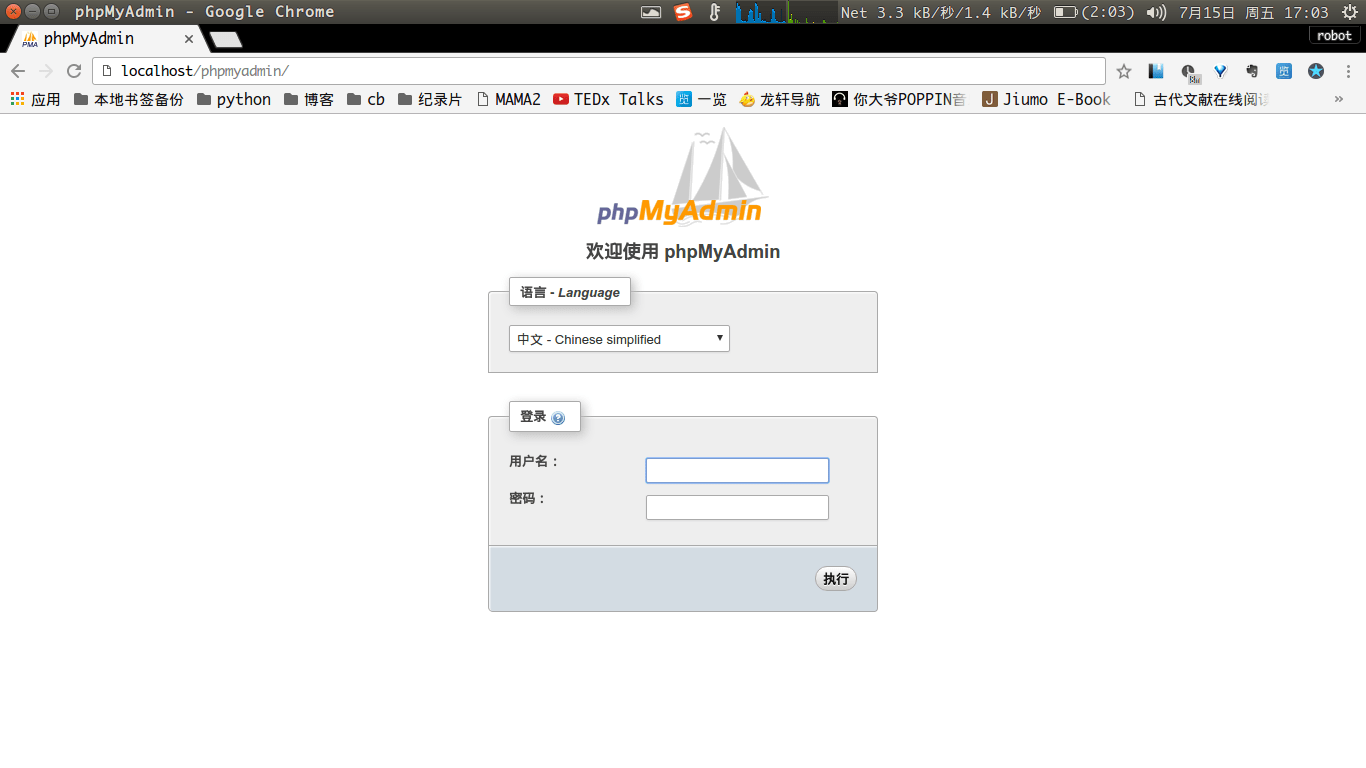
接着打开浏览器输入,如果出现下图说明安装成功可以使用。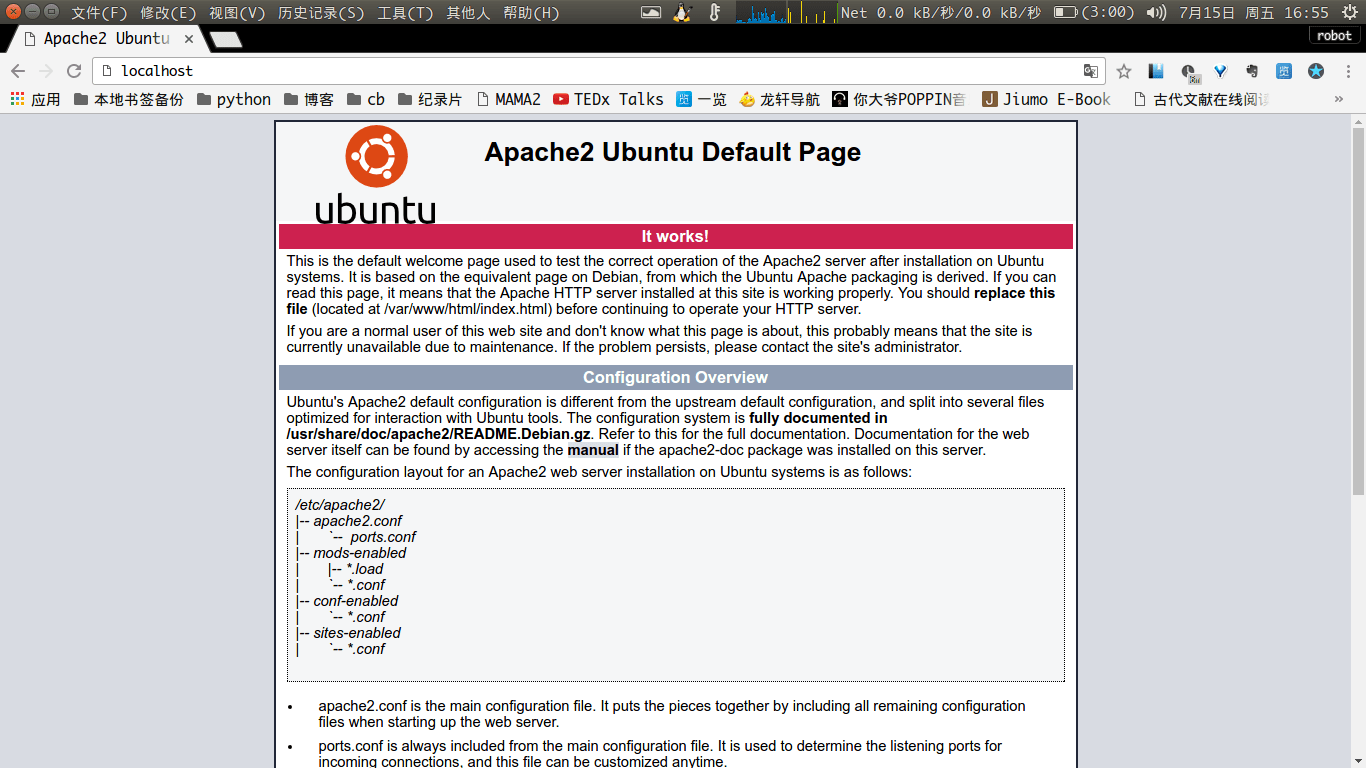
但是我在安装后出现了无法打开的问题,经过一番研究发现通过下列方法可以解决。
首先在终端里输入:
1 | sudo gedit /etc/apache2/httpd.conf |
如果你的这个文件(文件一般为空的)中加入ServerName localhost:80保存并退出。
重新打开,出现上图。
接着打开(ps:别忘了启动MySQL服务),出现下图情形,输入你的MySQL账号密码即可使用MySQL可视化工具进行操作。