- iTerm2 3.3.11
- Tmux 3.1b
问题
如图所示,在 iTerm2 中使用 Tmux 的复制模式就会报错。
解决方案
1 | $ defaults write com.googlecode.iterm2 NoSyncNeverAskAboutMouseReportingFrustration -bool true |
1 | ls -l |
这个 @ 属性是在 Finder 中对文件进行任意操作后被增加上的,把 @ 属性去掉后就可以正常双击 HTML 文件使用 Chrome 打开了。
清除一个文件的所有扩展属性的方法:
1 | xattr -c filename |
清除目录所有文件扩展属性的方法:
1 | xattr -rc dirpath |
清除当前目录下所有文件扩展属性的方法:
1 | xattr -rc . |
SSH 登录群晖,检测群晖当前用户主目录下是否有 .ssh 文件夹,如果没有使用下列命令创建:1 | mkdir ~/.ssh |
vim ~/.ssh/authorized_keys 将自己的 SSH 公钥粘贴进去,按 ESC 输入 wq 并回车保存。如果没有公钥的话,需要在自己电脑上使用 ssh-keygen -t rsa -C "MyName" 创建一个密钥,然后使用 cat ~/.ssh/id_rsa.pub 获取公钥信息,粘贴到群晖的 ~/.ssh/authorized_keys 文件中。
设置权限:
1 | chmod 755 ~ |
Ps: 群晖用户目录权限默认为 777,必须要修改为755才能免密登录
sshd_config 配置文件:1 | sudo vim /etc/ssh/sshd_config |
修改上述文件中以下几个配置:
1 | RSAAuthentication yes |
在群晖控制面板 -> 终端机和 SNMP 关闭再开启 SSH,即可免密登录群晖。
如果设置成功后为了安全起见,建议在保存好 密钥对(id_rsa 和 id_rsa.pub)的情况下,关闭密码登录群晖 SSH。
修改 sshd_config 配置文件:
1 | sudo vim /etc/ssh/sshd_config |
修改上述文件中以下配置:
1 | PasswordAuthentication no |
然后步骤 6 重启群晖 SSH 即可关闭密码登录群晖 SSH。
首先 SSH 登录群晖并进入 root 用户下:
1 | sudo -i |
执行下列一键安装脚本:
1 | sh -c "$(wget -O- https://raw.githubusercontent.com/Wooden-Robot/documents-for-fun/master/Synology/moments_ai_patch.sh)" -p install |
安装后重新启动 Moments 并全部重建索引。
卸载补丁执行下列命令:
1 | sh -c "$(wget -O- https://raw.githubusercontent.com/Wooden-Robot/documents-for-fun/master/Synology/moments_ai_patch.sh)" -p uninstall |
如果无法使用上面的 github 脚本!请关注公众号:WoodenRobot 回复 moments 获取国内安装和卸载命令!
直接在浏览器地址栏里输入:http://192.168.1.1/backupsettings.conf
,按下回车键后,将会把这个配置文件下载下来,这个配置文件就是光猫的配置文件,里面包含了管理员密码。
下载完毕后,将其打开,然后在里面搜索 AdminPassword,找到后,位于 <AdminPassword> 和 </AdminPassword> 之间的部分就是管理员密码了,一般为CUAdmin+八位数字,比如CUAdmin12345678。一串乱码的话 Q1VBZG1pbjEyMzQ1Njc4 是管理员密码使用了 Base64 编码了,可以这个网站解码:在线加密解密
宽带的拨号账号和密码在下列位置:
1 | <WANPPPConnection instance="1"> |
先找到 WANPPPConnection instance="1"下面几行后有一个 Username 和 Password 里面的 XXXXXX 和 YYYYYY 分别就为宽带拨号的账号和密码,密码可能也是 Base64 编码的,使用在线加密解密解码就可以了。
进入路由器更改普通用户密码页面:http://192.168.1.1/main.html?page=4
F12 打开开发者工具在网页源码里搜 pwdAdmin 后面就是管理员密码。
如图所示,在 iTerm2 中使用 Tmux 的复制模式就会报错。
1 | $ defaults write com.googlecode.iterm2 NoSyncNeverAskAboutMouseReportingFrustration -bool true |
终于忍受不了越来越慢的 zsh 启动速度,优化了一下 zsh 的启动速度。
.zshrc 配置文件如下:
1 |
|
其中 zsh-syntax-highlighting 和 zsh-autosuggestions 是通过下列方式安装:
1 | $ git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions |
通过配置文件可以看出,我安装了几个 oh my zsh 自带的插件以及 pyenv、nvm、virtualenvwrapper,安装插件以及其他程序的启动脚本是需要耗费时间的,测试一下 此时 zsh 的启动速度。
1 | $ \time zsh -i -c exit |
测了三次启动时间如下:
1 | 1.54 real 0.78 user 0.73 sys |
为了提高启动速度,先把 pyenv、nvm和virtualenvwrapper程序改为 lazyload,也就是不在 zsh 启动时就启动只在使用它们的时候启动。
使用 zsh-nvm 插件实现 nvm 的 lazyload。
下载插件:
1 | $ git clone https://github.com/lukechilds/zsh-nvm ~/.oh-my-zsh/custom/plugins/zsh-nvm |
然后在 .zshrc 文件中开启插件
1 | plugins=( |
删除 .zshrc 原有的 nvm 启动部分并开启 zsh-nvm 的 lazyload,加入:
1 | # zsh-nvm lazy load |
下载插件:
1 | $ git clone https://github.com/davidparsson/zsh-pyenv-lazy.git ~/.oh-my-zsh/custom/plugins/pyenv-lazy |
然后在 .zshrc 文件中开启插件
1 | plugins=( |
删除 .zshrc 原有的 pyenv 启动部分
virtualenvwrapper 启动部分;1 | export WORKON_HOME=$HOME/.virtualenvs |
1 |
|
优化完了测试一下现在的启动速度,老规矩测三次:
1 | 0.30 real 0.16 user 0.11 sys |
效果感人!!!
效果感人!!!
效果感人!!!
zsh 启动速度上来了但是新建一个 iTerm2 tab 好像还是有点慢做不到秒开。网上看到一个不知道什么原理的设置:
进入 iTerm2 的偏好设置里,在 Profiles 里编辑你的配置,在配置右侧的 General 选项卡里,Command 里选择为 Command,然后里边写入 /usr/bin/login -pfq xxx 其中 xxx 是你的用户名。
按照这个配置好,感觉是有那么一点点更快了(更慢了)?总之在我这里改动带来的体验并没有那么大,大家有兴趣可以去试试。
之前买了一个优酷路由宝 YK-L1c 在此记录一下刷机过程。最近又买了一个 YK-L1 发现刷机固件两个是通用的。
最新版的老毛子固件和 Breed 大家可以自行去下载,上述版本也可以使用,没有任何问题。
注意,用网线将PC连接路由宝,登录管理WEB页面 http://wifi.youku.com。或者默认的 192.168.11.1
步骤:更多设置——系统升级——手动升级——上传固件,上传的固件即为 Youku-L1c-0818-root.bin。 升级过程中不要中断路由宝与PC的连接,也不要中途断电。升级完成后路由器会重启,重启过程中耐心等待。
刷完第一步的固件后,实际上也已经 root 了,用户名:root 密码:admin
Ps: 密码不对的话就在路由器开机状态下长按路由器后面的 Reset 键重置路由器就可以了。
首先上传 breed 固件到路由器:
1 | scp breed-mt7620-youku-yk1.bin root@192.168.11.1:/tmp |
然后登录路由器:
1 | ssh root@192.168.11.1 |
在路由器 shell 中输入下列命令输入 breed:
1 | mtd write /tmp/breed-mt7620-youku-yk1.bin Bootloader |
路由断电后按住 reset 键,后通电,指示灯全闪后等 2 秒松开 reset 键,进入 Breed 管理界面 http://192.168.1.1 ,选择固件更新,使用 RT-N14U-GPIO-1-youku1-128M_3.4.3.9-099.trx 刷入老毛子。
上周末在赖信涛的邀请下,分享了 iredis 中 shell pipeline 实现的相关故事。第一次分享有点小紧张,提前好几天一直在准备 PPT 生怕自己讲不好,还好有惊无险完成了整个分享。这次分享主要由 iredis 的作者赖信涛和两位开发者 rhchen 和我通过 Zoom 的形式参与,内容辛姐帮我们录像上传到了 YouTube 和 B 站。
分享中提到的内容,以及分享的 slide,在下文 github 上可以找到。
slide: https://github.com/laixintao/myslides/tree/master/awesome-commandline
slide: https://github.com/Wooden-Robot/myslides/
协助开发 iredis pipeline feature 的始末
shell 的 pipeline原理,常用操作
python 的 subprocess 接口
如何参与开源项目
slide: https://github.com/laixintao/myslides/tree/master/bnf-by-rhchen
什么是 BNF,为什么要用它,能用它做什么?(编译原理的实践应用)
针对 iRedis 的解析需求, 如何设计 BNF? (处理”未输入完全”的字符串)
使用 SLY 解析输入和 iRedis 当前的解析方式的不同点比较
随着互联网技术的不断发展,用户量的不断增加,越来越多的业务场景需要用到分布式系统。而在分布式系统中访问共享资源就需要一种互斥机制,来防止彼此之间的互相干扰,以保证一致性,这个时候就需要使用分布式锁。
NX EX 参数本文主要讲解基于 Redis 实现的分布式锁
1 | # -*- coding: utf-8 -*- |
setnx 设置锁,如果该锁名之前不存在其他客户端的锁则加锁成功,接着设置锁的过期时间防止发生死锁并返回锁的唯一标示;setnx 和 expire 两个命令执行不是原子性的,可能会出现加锁成功但是设置超时时间失败出现死锁。如果不存在就给锁重新设置过期时间,存在就不断循环知道加锁时间超时加锁失败。watch 监听锁,防止解锁时出现删除其他人的锁;watch 就会删除失败,这样就不会出现删除了其他客户端锁的情况。如果你使用的 Redis 版本大于等于 2.6.12 版本,加锁的过程就可以进行简化。因为这个版本以后的 Redis set 操作支持 EX 和 NX 参数,是一个原子性的操作。
1 | # -*- coding: utf-8 -*- |
可能你也发现了解锁过程在代码逻辑上稍微有点复杂,别着急,我们可以使用 Lua 脚本实现原子性操作从而简化解锁过程。
1 | # -*- coding: utf-8 -*- |
截至到目前,我们已经有较好的方法获取锁和释放锁。基于Redis单实例,假设这个单实例总是可用,这种方法已经足够安全。但是如果 Redis 主节点挂了就会出现一些问题,比如主节点加锁后没有同步到从节点,从节点升为主节点,就会出现锁的丢失。如果你想要使用更加安全的 Redis 分布式锁实现可以参考一下 Redlock 的实现。
python 所有加载的模块信息都存放在 sys.modules 结构中,当 import 一个模块时,会按如下步骤来进行
import A,检查 sys.modules 中是否已经有 A,如果有则不加载,如果没有则为 A 创建 module 对象,并加载 Afrom A import B,先为 A 创建 module 对象,再解析A,从中寻找B并填充到 A 的 __dict__ 中绝对导入的格式为 import A.B 或 from A import B,相对导入格式为 from . import B 或 from ..A import B,. 代表当前模块,.. 代表上层模块,... 代表上上层模块,依次类推。
相对导入可以避免硬编码带来的维护问题,例如我们改了某一顶层包的名,那么其子包所有的导入就都不能用了。但是 存在相对导入语句的模块,不能直接运行,否则会有异常:
1 | ImportError: attempted relative import with no known parent package |
这是什么原因呢?我们需要先来了解下导入模块时的一些规则:
在没有明确指定包结构的情况下,Python 是根据 __name__ 来决定一个模块在包中的结构的,如果是 __main__ 则它本身是顶层模块,没有包结构,如果是 A.B.C 结构,那么顶层模块是 A。基本上遵循这样的原则:
如果一个模块被直接运行,则它自己为顶层模块,不存在层次结构,所以找不到其他的相对路径。
Python2.x 缺省为相对路径导入,Python3.x 缺省为绝对路径导入。绝对导入可以避免导入子包覆盖掉标准库模块(由于名字相同,发生冲突)。如果在 Python2.x 中要默认使用绝对导入,可以在文件开头加入如下语句:
1 | from __future__ import absolute_import |
这句 import 并不是指将所有的导入视为绝对导入,而是指禁用 implicit relative import(隐式相对导入), 但并不会禁掉 explicit relative import(显示相对导入)。
那么到底什么是隐式相对导入,什么又是显示的相对导入呢?我们来看一个例子,假设有如下包结构:
1 | thing |
那么如果在 stool 中引用 bench,则有如下几种方式:
1 | import bench # 此为 implicit relative import |
隐式相对就是没有告诉解释器相对于谁,但默认相对与当前模块;而显示相对则明确告诉解释器相对于谁来导入。以上导入方式的第三种,才是官方推荐的,第一种是官方强烈不推荐的,Python3 中已经被废弃,这种方式只能用于导入 path 中的模块。
相对与绝对仅针对包内导入而言
最后再次强调,相对导入与绝对导入仅针对于包内导入而言,要不然本文所讨论的内容就没有意义。所谓的包,就是包含 __init__.py 文件的目录,该文件在包导入时会被首先执行,该文件可以为空,也可以在其中加入任意合法的 Python 代码。
相对导入可以避免硬编码,对于包的维护是友好的。绝对导入可以避免与标准库命名的冲突,实际上也不推荐自定义模块与标准库命令相同。
前面提到含有相对导入的模块不能被直接运行,实际上含有绝对导入的模块也不能被直接运行,会出现 ImportError:
1 | ImportError: No module named XXX |
这与绝对导入时是一样的原因。要运行包中包含绝对导入和相对导入的模块,可以用 python -m A.B.C 告诉解释器模块的层次结构。
有人可能会问:假如有两个模块 a.py 和 b.py 放在同一个目录下,为什么能在 b.py 中 import a 呢?
这是因为这两个文件所在的目录不是一个包,那么每一个 python 文件都是一个独立的、可以直接被其他模块导入的模块,就像你导入标准库一样,它们不存在相对导入和绝对导入的问题。相对导入与绝对导入仅用于包内部。
]]>本文转载于:Python 相对导入与绝对导入
使用 brew升级 openssl 后打开 zsh shell 后遇到下面报错:
1 | ERROR:root:code for hash md5 was not found. |
1 | $ brew reinstall python@2 |
如果其他版本的 Python 也出现无法使用的情况请重新安装一次。例如使用 pyenv 安装的 python 需要使用下列命令重新安装:
1 | pyenv install -f 3.6.3 |
1 | $ sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \ |
1 | $ sudo yum install @development zlib-devel bzip2 bzip2-devel readline-devel sqlite \ |
1 | $ curl -O https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tar.xz |
首先解压源码包
1 | $ tar -Jxvf Python-3.8.1.tar.xz |
编译安装
1 | $ ./configure --prefix=/usr/local/python3 --enable-optimizations |
注:--enable-optimizations 配置项用于提高 Python 安装后的性能,使用会导致编译速度稍慢
1 | $ ln -s /usr/local/python3/bin/python3.8 /usr/bin/python3 |
命令行输入 python3 -V 查看是否安装成功。
sudo。光网络终端(英语:Optical Network Terminals,俗称光猫或光 modem),是指通过光纤介质进行传输,将光信号调制解调为其他协议信号的网络设备。光猫设备作为大型局域网、城域网和广域网的中继传输设备。
光猫的主要功能为信号转换,它的后端接口除了连接电脑,还可以连接电视或电话。
路由器(英语:Router,又称路径器)是一种电讯网络设备,提供路由与转送两种重要机制,可以决定数据包从来源端到目的端所经过的路由路径(host 到 host 之间的传输路径),这个过程称为路由;将路由器输入端的数据包移送至适当的路由器输出端(在路由器内部进行),这称为转送。路由工作在 OSI 模型的第三层——即网络层,例如网际协议(IP)。
路由器就是连接两个以上个别网络的设备。
由于位于两个或更多个网络的交汇处,从而可在它们之间传递分组(一种数据的组织形式)。路由器与交换机在概念上有一定重叠但也有不同:交换机泛指工作于任何网络层次的数据中继设备(尽管多指网桥),而路由器则更专注于网络层。
路由器与交换机的差别,路由器是属于 OSI 第三层的产品,交換机是 OSI 第二层的产品。第二层的产品功能在于,将网络上各个计算机的 MAC 地址记在 MAC 地址表中,当局域网中的计算机要经过交換机去交换传递数据时,就查询交換机上的 MAC 地址表中的信息,将数据包发送给指定的计算机,而不会像第一层的产品(如集线器)每台在网络中的计算机都发送。而路由器除了有交換机的功能外,更拥有路由表作为发送数据包时的依据,在有多种选择的路径中选择最佳的路径。此外,并可以连接两个以上不同网段的网络,而交換机只能连接两个。并具有 IP 分享的功能,如:区分哪些数据包是要发送至 WAN。路由表存储了(向前往)某一网络的最佳路径,该路径的“路由度量值”以及下一个(跳路由器)。参考条目路由获得这个过程的详细描述。
路由器通常包含一个 WAN 口多个 LAN 口(PS: 有些特殊的路由器包含多个 WAN 口)。
广域网(英语:Wide Area Network,缩写为 WAN),又称广域网、外网、公网。是连接不同地区局域网或城域网计算机通信的远程网。通常跨接很大的物理范围,所覆盖的范围从几十公里到几千公里,它能连接多个地区、城市和国家,或横跨几个洲并能提供远距离通信,形成国际性的远程网络。广域网并不等同于互联网。
局域网(Local Area Network,简称 LAN)是连接住宅、学校、实验室、大学校园或办公大楼等有限区域内计算机的计算机网络。相比之下,广域网(WAN)不仅覆盖较大的地理距离,而且还通常涉及固接专线和对于互联网的链接。 相比来说互联网则更为广阔,是连接全球商业和个人计算机的系统。
通常情况下,宽带安装好以后使用网线连接光猫和路由器 WAN 口,其他设备连接路由器 LAN 口或者无线网络即可浏览互联网。
该模式下路由器的无线网卡就像一个”无线 HUB”,负责建立无线路由器和电脑之间的数据链路(相当于无形的网线)。正常情况下,家用的无线路由器的无线连接都默认工作在此模式下。
像笔记本电脑上的无线网卡那样工作,仅连接其它的无线网络,而不发射自己的无线网络信号。对于无线路由器来说,这种模式相当于启用了一个无线的 WAN 口,且下面的电脑只能通过有线方式接到此设备。内部的LAN口组成的局域网和连接上的无线网段处于相同的 IP 地址段。内部的 DHCP 请求也会被转发到主无线网络上。
和“客户端”模式一样,相当于启用了一个无线的 WAN 口,且下面的电脑只能通过有线方式接到此设备。不过,该模式下无线路由器仍然提供 DHCP 及 NAT 功能,内部 LAN 口组成的单独 IP 地址段局域网,通过无线路由器上自己的网关,连上外部主网络。
Adhoc 有个形象的比喻,就像是将两台电脑之间直接找根网线连起来,只不过在这里这根网线是个无线的。最常见的使用adhoc连接的设备多数是一些手持游戏机。该模式在无线路由器上使用的场合比较罕见。
顾名思义,中继就是一边是接受信号,一边又发射自己的无线信号。在这种模式下无线路由器以无线网卡客户身份接入主 AP,然后再以新增虚拟界面(Virtual Interfaces)来为客户端提供无线接入。该模式的最大意义在于可以解决无线信号受到距离或者障碍物的影响不能传输到更远的问题。
接入到该无线路由器上的电脑终端,是和主无线网网络处在相同的 IP 地址段。内部的 DHCP 请求,也会被转发到主无线网络上。
和”中继”模式一样,可以解决无线信号受到距离或者障碍物的影响不能传输到更远的问题。不过,这种模式下无线路由器仍然提供 DHCP 及 NAT 功能,即所有的内部 LAN 口以及无线客户接入组成的是一个单独的局域网网段。
动态主机设置协议(英语:Dynamic Host Configuration Protocol,缩写:DHCP)是一个用于局域网的网络协议,位于 OSI 模型的应用层,使用 UDP 协议工作,主要有两个用途:
- 用于内部网或网络服务供应商自动分配IP地址给用户
- 用于内部网管理员作为对所有计算机作中央管理的手段
当一台机器新加入一个网络的时候,肯定一脸懵,啥情况都不知道,只知道自己的 MAC 地址。怎么办?先吼一句,我来啦,有人吗?这时候的沟通基本靠“吼”。这一步,我们称为 DHCP Discover。
新来的机器使用 IP 地址 0.0.0.0 发送了一个广播包,目的 IP 地址为 255.255.255.255。广播包封装了 UDP,UDP 封装了 BOOTP。其实 DHCP 是 BOOTP 的增强版,但是如果你去抓包的话,很可能看到的名称还是 BOOTP 协议。
在这个广播包里面,新人大声喊:我是新来的(Boot request),我的 MAC 地址是这个,我还没有 IP,谁能给租给我个 IP 地址!
格式就像这样: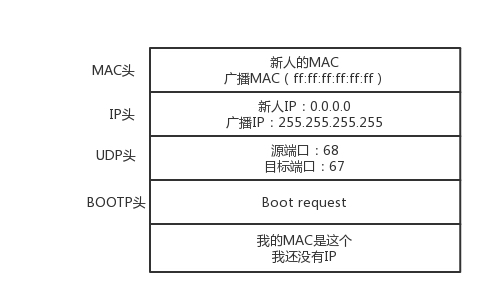
如果一个网络管理员在网络里面配置了 DHCP Server 的话,他就相当于这些 IP 的管理员。他立刻能知道来了一个“新人”。这个时候,我们可以体会 MAC 地址唯一的重要性了。当一台机器带着自己的 MAC 地址加入一个网络的时候,MAC 是它唯一的身份,如果连这个都重复了,就没办法配置了。
只有 MAC 唯一,IP 管理员才能知道这是一个新人,需要租给它一个 IP 地址,这个过程我们称为 DHCP Offer。同时,DHCP Server 为此客户保留为它提供的 IP 地址,从而不会为其他 DHCP 客户分配此 IP 地址。
DHCP Offer 的格式就像这样,里面有给新人分配的地址。
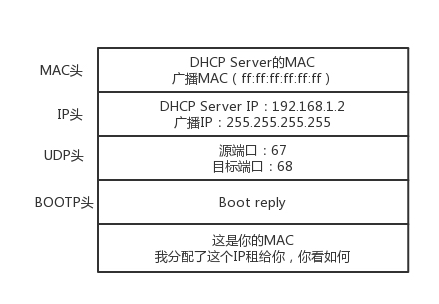
DHCP Server 仍然使用广播地址作为目的地址,因为,此时请求分配 IP 的新人还没有自己的 IP。DHCP Server 回复说,我分配了一个可用的 IP 给你,你看如何?除此之外,服务器还发送了子网掩码、网关和 IP 地址租用期等信息。
新来的机器很开心,它的“吼”得到了回复,并且有人愿意租给它一个 IP 地址了,这意味着它可以在网络上立足了。当然更令人开心的是,如果有多个 DHCP Server,这台新机器会收到多个 IP 地址,简直受宠若惊。
它会选择其中一个 DHCP Offer,一般是最先到达的那个,并且会向网络发送一个 DHCP Request 广播数据包,包中包含客户端的 MAC 地址、接受的租约中的 IP 地址、提供此租约的 DHCP 服务器地址等,并告诉所有 DHCP Server 它将接受哪一台服务器提供的 IP 地址,告诉其他 DHCP 服务器,谢谢你们的接纳,并请求撤销它们提供的 IP 地址,以便提供给下一个 IP 租用请求者。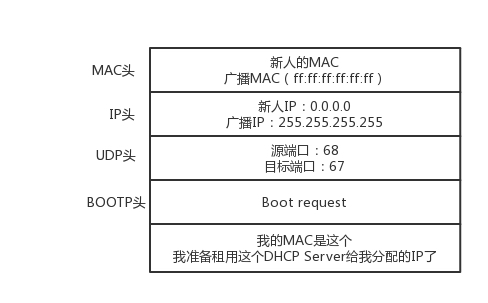
此时,由于还没有得到 DHCP Server 的最后确认,客户端仍然使用 0.0.0.0 为源 IP 地址、255.255.255.255 为目标地址进行广播。在 BOOTP 里面,接受某个 DHCP Server 的分配的 IP。
当 DHCP Server 接收到客户机的 DHCP request 之后,会广播返回给客户机一个 DHCP ACK 消息包,表明已经接受客户机的选择,并将这一 IP 地址的合法租用信息和其他的配置信息都放入该广播包,发给客户机,欢迎它加入网络大家庭。
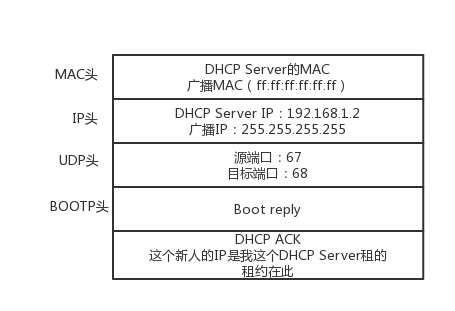
最终租约达成的时候,还是需要广播一下,让大家都知道。
既然是租房子,就是有租期的。租期到了,管理员就要将 IP 收回。
如果不用的话,收回就收回了。就像你租房子一样,如果还要续租的话,不能到了时间再续租,而是要提前一段时间给房东说。DHCP 也是这样。
客户机会在租期过去 50% 的时候,直接向为其提供 IP 地址的 DHCP Server 发送 DHCP request 消息包。客户机接收到该服务器回应的 DHCP ACK 消息包,会根据包中所提供的新的租期以及其他已经更新的 TCP/IP 参数,更新自己的配置。这样,IP 租用更新就完成了。
好了,一切看起来完美。DHCP 协议大部分人都知道,但是其实里面隐藏着一个细节,很多人可能不会去注意。接下来,我就讲一个有意思的事情:网络管理员不仅能自动分配 IP 地址,还能帮你自动安装操作系统!
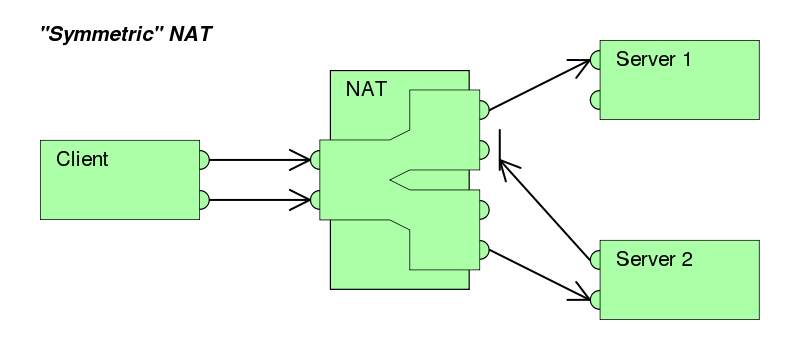
网络地址转换(英语:Network Address Translation,缩写:NAT;又称网络掩蔽、IP 掩蔽)在计算机网络中是一种在IP数据包通过路由器或防火墙时重写来源 IP 地址或目的 IP 地址的技术。这种技术被普遍使用在有多台主机但只通过一个公有 IP 地址访问因特网的私有网络中。它是一个方便且得到了广泛应用的技术。当然,NAT 也让主机之间的通信变得复杂,导致了通信效率的降低。
对于 TCP/UDP 使用
Host ‘s 私有 IPv4 + Port <——> NAT 公网 IPv4 + Port
对于ICMP使用
Host ‘s 私有 IPv4 + session ID <——> NAT 公网 IPv4 + session ID
规则其实非常好理解,由于 session ID 在 NAT 设备上是独一无二的,所以NAT可以很容易区别局域网内部的不同 host。
至于其它传输协议,NAT 使用的也是类似 session ID 的转换规则,即使用可以将不同 host 轻易分辨出来的字段做键值(KEY),动态创建映射表项,做双向的地址+ KEY 的转换。
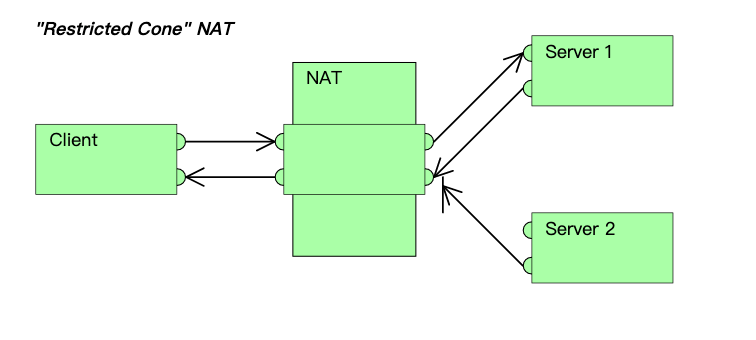
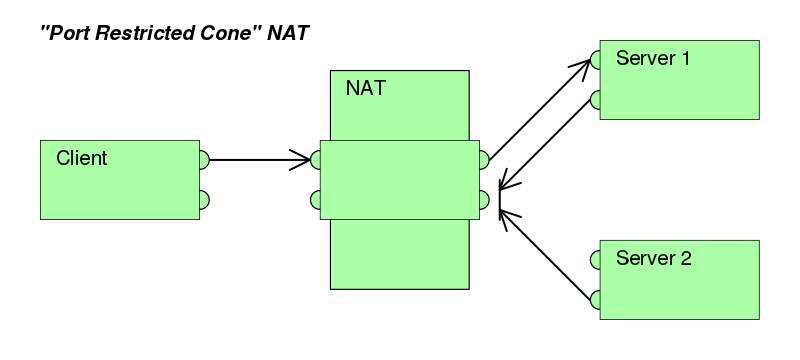
类似受限制锥形NAT(Restricted cone NAT),但是还有端口限制。
通用即插即用(英语:Universal Plug and Play,简称UPnP)是由“通用即插即用论坛”(UPnP™ Forum)推广的一套网络协议。该协议的目标是使家庭网络(数据共享、通信和娱乐)和公司网络中的各种设备能够相互无缝连接,并简化相关网络的实现。UPnP 通过定义和发布基于开放、因特网通讯网协议标准的 UPnP 设备控制协议来实现这一目标。
可以理解为有了 UPnP 软件可以根据需求让路由器进行动态地进行端口映射。而不是你去路由器后台一个个手动设置。
一般来说,我们希望 NAT 层数越少越好。每多一层 NAT 就意味着更加复杂的情况与配置。依旧是典型的网络拓扑:
入户光纤① → 猫② → 路由器③ → 终端设备
我们目标是把 NAT 降到1层(只有③),当然这是目标,但不是必须的。
拥有公网 IP 对于 P2P 应用来说绝对是一个基础要求,这可以省掉许多麻烦(使①不发生 NAT)。如何确定自己是不是公网 IP 也很简单。访问这里你可以得到一个 IP 地址,把它与路由器中显示的 WAN 口 IP 进行比较,如果一致那么就是公网 IP 了。
如果不一致,那么只能联系运营商,自己是没有办法的。一般来说一级运营商(电信/联通)比较容易,而一些二级甚至三级运营商(长城)就没什么希望了。如果拿不到公网 IP,只能期望运营商不要把 NAT 类型限制太死吧。
现在原来越多的猫“越权管理”,增加了路由功能,也就是说猫和路由器一体化了。每一个路由器可以理解为一层网络,我们不希望层数过多。同时猫的路由功能往往不完善,难以进行高级配置。而桥接模式就是让猫回归本质,只负责信号转换。
区分路由与桥接模式最方便的办法是:如果你的路由器(电脑)直接连到猫上就可以上网,那么是路由模式;如果路由器需要配置 PPPoE 拨号那么就是桥接模式。
一般来说更改模式需要猫的超级密码,这个用户是没有的。请联系运营商客服请求修改。改为桥接后②也不会发生 NAT 了。
警告:没能力折腾的不建议自己破解改。更改桥接模式之后记得重新配置路由器,输入宽带账号密码才可以正常上网。
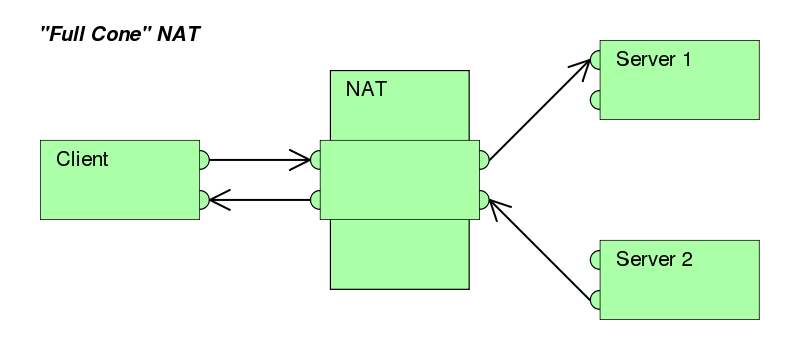
首先要修改 NAT 类型,并不是所有的路由器或者路由器系统都支持这一设置。打开 NAT 并将类型设置为最宽松的 NAT1(Full cone NAT)。
接着启用 UPnP,绝大部分路由器都支持的,耐心找一找。如果真的不支持那我建议换路由器。
如果不支持上述的 NAT 类型设置,我们还有一个大招。大部分的路由器都支持 DMZ (非军事化区),DMZ 指定的设备完全暴露在公网上。但是一个网络一般只能够设置1个 DMZ,显然如果设置多个路由器就不知道应该把数据包交给谁了。由于 DMZ 是和 IP 绑定的,而 IP 是动态分配的。所有首先我们将 IP 与 MAC 绑定(不同的路由器设置不同),然后将此 IP 设置为 DMZ 即可。
最后如果你的系统启用了防火墙那么记得将需要的程序添加例外,或者关闭防火墙(不推荐)。最后进行测试,NAT 类型应该可以提升到完全圆锥型NAT(Full cone NAT)。
以 hiboy 的老毛子 Padavan 系统路由器为例,介绍一下无线中继和桥接的异同:
1 | $ mv /var/packages/SynologyMoments/target/usr/lib/libsynophoto-plugin-detection.so /var/packages/SynologyMoments/target/usr/lib/libsynophoto-plugin-detection.so.bak |
/var/packages/SynologyMoments/target/usr/lib/ 路径下注: 修复 bug 的 libsynophoto-plugin-detection.so 文件来源于 1.2.1-0646 版本的 Moments
蜗牛星际装了黑群晖后,加上家里的宽带是 200M 带宽,以前的 Newifi mini 百兆路由器已经不能满足需求了,于是闲鱼入手了 TOTOLINK A3004NS 千兆路由器。
1. 进路由记录下LAN, WAN, 2.G, 5G 的 MAC 地址备用(Ps: 最好记录一下,后面可能会出现刷机后 Mac 地址改变,需要用来复原)
2.原厂固件下刷入荒野无灯大神 A3004NS Padavan 直刷固件
路由器地址为:192.168.88.1
登录账号密码为:admin/admin
3.查看固件分区
1 | [A3004NS /opt/home/admin]# cat /proc/mtd |
4.重启,备份EEPROM
ssh 登录路由器,使用以下命令进行备份:
1 | $ dd if=/dev/mtd2 of=/tmp/Factory.bin |
Factory 就是 EEPROM。
此时可以将其他分区用同样的方法都备份一下,以备不时之需。备份好需要从路由器中将备份数据下载到本地,可以用 ftp、scp等命令行命令,也可以使用 FileZilla 工具。
这是我用 dd 命令备份的所有分区信息:dd 全分区备份。
5.下载最新版的 A3004NS breed 固件并上传到路由器的 /tmp 路径下。
6.通过 ssh 登录路由器执行:
1 | $ mtd_write write /tmp/breed-mt7621-totolink-a3004ns.bin Bootloader |
7.完了将路由器断电。然后按住前面板上的 WPS 按钮通电,多按一会儿。这时路由器网关又变成了 192.168.1.1。使用浏览器打开这个地址就可以进入 breed 后台。
8.进入 Breed 后,记得先备份 EEPROM。这个很重要,后面如果刷固件刷出问题需要这个来还原。
1.下载 hiboy Padavan 最新版固件:http://opt.cn2qq.com/padavan/
2.进入 Breed,点击“固件更新”-〉“常规固件”:
固件,并选择我们下载的固件。EEPROM,并选择刚刚用 Breed 备份的 EEPROM公版(0x50000)上传按钮进行安装。
admin/admin3.如果MAC地址改变,进入 Breed 把记下来的 MAC 地址填进去并保存。
在公司科学上网使用谷歌经常出现很长一段时间访问不了,严重影响工作效率,没办法只能自己搭建一个镜像网站。
1 | sudo apt install nginx |
在 /etc/nginx/sites-enabled 文件夹内新增 google.conf 配置文件,配置文件内容为:
1 | server { |
注:请手动更改配置中的 www.example.com 为自己的域名地址
使用下列命令重新载入配置
1 | $ nginx -s reload |
将自己的域名添加一条指向该台服务器 IP 的 DNS 解析记录,访问域名即可实现访问谷歌。
如果不想自己的谷歌镜像被别人乱用,可以增加 Basic Auth 来限制其他人使用。
使用下列命令生成密码:
1 | printf "your_username:$(openssl passwd -crypt your_password)\n" >> /etc/nginx/conf.d/passwd |
用 vim 修改刚刚的配置文件
1 | vim /etc/nginx/sites-enabled/google.conf |
增加下列内容
1 | ... |
然后 nginx -s reload 重启 Nginx 生效。
家里用蜗牛星际组装了一个黑群晖,之前用 Zerotier-one 做内网穿透从外网连接到群晖,后来发现 Zertier-one 的 P2P 的成功率很低,速度很慢,看了一下光猫发现宽带有公网 IP,于是更换光猫为桥接模式,使用路由器拨号上网,路由器做端口转发,直接通过公网 IP 连接群晖,在此记录一下 中兴 ZXHN F677V2 光猫改桥接的方法。Ps: 淘宝要几十块,穷就自己动手啦 : )
连接路由器的网络,访问 http://192.168.1.1/cu.html;
输入超级管理员密码进入超级管理员后台,密码默认为:CUAdmin(Ps: 我是打装宽带的师傅电话要的,不对的话可以问师傅要);
在基本配置中选择上行线路配置,记录名为 x_INTERNET_R_VID_y 原本 PPPoE 模式中的配置信息,特别是 VLAN ID 值(Ps: x和y的值每个人可能不一样)
添加一个新的 Bridge 模式的连接,除了模式之前其他的配置设置为和之前 PPPoE 模式相同,切记 VLAN ID 值一定要相同;
删除原来的两个连接,一个是 x_TR069_R_VID_y,一个是 x_INTERNET_R_VID_y。
路由器使用原本的宽带账号密码拨号上网即可;
如果拨号后连接不成功,可以关闭光猫几分钟再开启进行尝试。
本文转载于:Python的Buffer机制
Python版本: 3.7.1(3.7以上版本)
清空 PYTHONUNBUFFERED 环境变量(默认是空的,不过以防万一还是清空下)
cmd 清空
1 | set PYTHONUNBUFFERED="" |
powershell 清空
1 | $env:PYTHONUNBUFFERED="" |
bash 清空
1 | export PYTHONUNBUFFERED="" |
将下面内容保存到 test.py 中,执行下面的语句
1 | import sys |
执行 python test.py, 输出 stderr1 stderr2 stdout1 stdout2
执行 python -u test.py, 输出 stdout1 stderr1 stdout2 stderr2
对于 stderr,其名称是标准错误输出文件,标准里规定是无缓冲的,每次输出一个字符就直接显示到屏幕上
而对于 stdout,其名称是标准输出文件,UNIX标准里规定是行缓冲的,遇到换行或者积累到一定的大小一次性输出到屏幕上
由于默认情况下,缓冲区是开启的。
因此 stdout 的输出会先存入到一个 buffer 中,而 stderr 的内容是直接显示的,因此默认输出顺序是 stderr1 stderr2 stdout1 stdout2
当将其改为
1 | import sys |
由于 stdout 是行缓冲,遇到换行后也是直接输出,因此此时输出内容就是正常顺序
对于 Python 而言,其规定如下:
关于该改动的讨论: Improve documentation of stdout/stderr buffering in Python 3.x
而对于 -u 参数:
而当 PYTHONPATH 不为空,视为使用了 -u 参数
虽然输出结果与行缓冲与无缓冲的结果相同,但是仍然需要注意这里并非是如同规范那样定义
一般来说,第一次接触缓冲区应该都是C语言读入部分
比如如果要有用户交互输入数据,需要分析输入内容,可能会牵扯到换行的处理
当用户一次性输入很多数据时,这些数据都会被存放在输入缓冲区内,每次使用 getchar();或者 scanf("%c", &c);会从中取出一个字符出来
这时,如果输入末尾有无效输入,比如用户多打了个空格才换行等奇怪的操作,可能会导致输入缓冲区留下一部分数据,从而导致下一次处理数据出错
这时,往往要使用 fflush(stdin);在每次读入前清空缓冲区,以确保读到的数据是用户刚刚输入的内容
在 Python 中,最常见的操作是使用 flask、django 时,后台打印 log。
当同时有两个请求送达,两个打印 log 的操作同时写入输出缓冲区,很可能你看到的就是两个 log 混杂在一起的内容,这时为了保证 log 的完整以及有序,就应该关闭缓冲区
而在Python中,关闭缓冲区有三种方法:
sys.stdout.flush()python -u xxx.pyset PYTHONUNBUFFERED=""缓冲区(buffer)原本是用于中和内外存读取速度不同而设计的一个缓冲
因此当读写速度与运算、处理速度不匹配时就应该使用缓冲区
如大量写入文件,尽管可以使用 "n".join(data_list) 来将数据拼接成文本一次写入,但是有时候可能会由于异步、数据结构过于复杂,需要用多个 f.write() 来写入文件,这时就需要使用 buffer
将要写到文件的数据先存入内存中,关闭文件时一次性写入,从而减少了 io 操作次数
另外,引起该篇博文的原因代码是:
1 | print(";".join([str(i) for i in range(10000)])) |
这段代码在 Windows 环境下的 Python3.9 以下版本使用 python -u test.py 会导致奇怪的截断
简单解释就是 Windows 7 以下的控制台对写出有限制(64KiB),因此 python 会尝试将输出内容除以 2 来输出
最终导致输出内容被截断
该“特性”将在Python3.9被移除
相关讨论: StackOverflow: Why does this code print a different result between Windows and Linux?
蜗牛星际装了黑群晖,下了几部蓝光电影,播放的时候确显示“不支持当前所选音频的文件格式,因此无法播放视频。请尝试其它音轨,确定其是否支持”。经过查询得知这两个音轨是需要授权使用的,群晖应该没有给授权费,所以在后续的 Video Station 版本中禁用了这些音轨。
套件中心,点击设置 —> 常规,在信任层级中选择任何发行者;套件来源,选择 新增 添加第三方源 http://packages.synocommunity.com/ 在刚刚添加的第三方套件源中找到 ffmpeg 进行安装。
Video Station;video station 2.3.4-1468 版本手动安装;Video Station 就可以播放 DTS 和 eac3 音轨的视频了。PS:使用这个方案会失去最新版 video station 的特性,比如倍速播放、电视剧搜刮信息更全的遗憾
适用于最新 2.4.9-1626 版 Video Station
首先 SSH 登录群晖并进入 root 用户下:
1 | sudo -i |
执行下列一键安装脚本:
1 | sh -c "$(wget -O- https://raw.githubusercontent.com/Wooden-Robot/documents-for-fun/master/Synology/ffmpeg_dts_eac3_patch.sh)" -p install |
安装后重新启动 Video Station 就可以播放 DTS 和 eac3 音轨的视频了。
卸载补丁执行下列命令:
1 | sh -c "$(wget -O- https://raw.githubusercontent.com/Wooden-Robot/documents-for-fun/master/Synology/ffmpeg_dts_eac3_patch.sh)" -p uninstall |
如果无法使用上面的 github 脚本!请关注公众号:WoodenRobot 回复 dts 获取国内安装和卸载命令!
以访问”baidu.com”为例,当你按下“b”键,浏览器接收到这个消息之后,会触发自动完成机制。浏览器根据自己的算法,以及你是否处于隐私浏览模式,会在浏览器的地址框下方给出输入建议。大部分算法会优先考虑根据你的搜索历史和书签等内容给出建议。
ARP Request:
1 | Sender MAC: interface:mac:address:here |
根据连接主机和路由器的硬件类型不同,可以分为以下几种情况:
直连:
集线器:
ARP Reply 。交换机:
ARP ReplyARP Reply:
1 | Sender MAC: target:mac:address:here |
现在我们有了 DNS 服务器或者默认网关的 IP 地址,我们可以继续 DNS 请求了:
当浏览器得到了目标服务器的 IP 地址,以及 URL 中给出来端口号(http 协议默认端口号是 80, https 默认端口号是 443),它会调用系统库函数 socket ,请求一个 TCP 流套接字,对应的参数是 AF_INET/AF_INET6 和 SOCK_STREAM。
这个请求首先被交给传输层,在传输层请求被封装成 TCP segment。目标端口会被加入头部,源端口会在系统内核的动态端口范围内选取(Linux下是ip_local_port_range)
TCP segment 被送往网络层,网络层会在其中再加入一个 IP 头部,里面包含了目标服务器的IP地址以及本机的IP地址,把它封装成一个IP packet。
这个 TCP packet 接下来会进入链路层,链路层会在封包中加入 frame 头部,里面包含了本地内置网卡的MAC地址以及网关(本地路由器)的 MAC 地址。像前面说的一样,如果内核不知道网关的 MAC 地址,它必须进行 ARP 广播来查询其地址。
到了现在,TCP 封包已经准备好了,可以使用下面的方式进行传输:
对于大部分家庭网络和小型企业网络来说,封包会从本地计算机出发,经过本地网络,再通过调制解调器把数字信号转换成模拟信号,使其适于在电话线路,有线电视光缆和无线电话线路上传输。在传输线路的另一端,是另外一个调制解调器,它把模拟信号转换回数字信号,交由下一个网络节点处理。节点的目标地址和源地址将在后面讨论。
大型企业和比较新的住宅通常使用光纤或直接以太网连接,这种情况下信号一直是数字的,会被直接传到下一个 网络节点 进行处理。
最终封包会到达管理本地子网的路由器。在那里出发,它会继续经过自治区域(autonomous system, 缩写 AS)的边界路由器,其他自治区域,最终到达目标服务器。一路上经过的这些路由器会从IP数据报头部里提取出目标地址,并将封包正确地路由到下一个目的地。IP数据报头部 time to live (TTL) 域的值每经过一个路由器就减1,如果封包的TTL变为0,或者路由器由于网络拥堵等原因封包队列满了,那么这个包会被路由器丢弃。
上面的发送和接受过程在 TCP 连接期间会发生很多次:
客户端选择一个初始序列号(ISN),将设置了 SYN 位的封包发送给服务器端,表明自己要建立连接并设置了初始序列号
服务器端接收到 SYN 包,如果它可以建立连接:
客户端通过发送下面一个封包来确认这次连接:
数据通过下面的方式传输:
关闭连接时:
客户端发送一个 ClientHello 消息到服务器端,消息中同时包含了它的 Transport Layer Security (TLS) 版本,可用的加密算法和压缩算法。
服务器端向客户端返回一个 ServerHello 消息,消息中包含了服务器端的TLS版本,服务器所选择的加密和压缩算法,以及数字证书认证机构(Certificate Authority,缩写 CA)签发的服务器公开证书,证书中包含了公钥。客户端会使用这个公钥加密接下来的握手过程,直到协商生成一个新的对称密钥
客户端根据自己的信任CA列表,验证服务器端的证书是否可信。如果认为可信,客户端会生成一串伪随机数,使用服务器的公钥加密它。这串随机数会被用于生成新的对称密钥
服务器端使用自己的私钥解密上面提到的随机数,然后使用这串随机数生成自己的对称主密钥
客户端发送一个 Finished 消息给服务器端,使用对称密钥加密这次通讯的一个散列值
服务器端生成自己的 hash 值,然后解密客户端发送来的信息,检查这两个值是否对应。如果对应,就向客户端发送一个 Finished 消息,也使用协商好的对称密钥加密
从现在开始,接下来整个 TLS 会话都使用对称秘钥进行加密,传输应用层(HTTP)内容
如果浏览器使用 HTTP 协议,它会向服务器发送这样的一个请求:
1 | GET / HTTP/1.1 |
“其他头部”包含了一系列的由冒号分割开的键值对,它们的格式符合 HTTP 协议标准,它们之间由一个换行符分割开来。(这里我们假设浏览器没有违反 HTTP 协议标准的 bug,同时假设浏览器使用 HTTP/1.1 协议,不然的话头部可能不包含 Host 字段,同时 GET 请求中的版本号会变成 HTTP/1.0 或者 HTTP/0.9 。)
HTTP/1.1 定义了“关闭连接”的选项 “close”,发送者使用这个选项指示这次连接在响应结束之后会断开。例如:
Connection:close
不支持持久连接的 HTTP/1.1 应用必须在每条消息中都包含 “close” 选项。
在发送完这些请求和头部之后,浏览器发送一个换行符,表示要发送的内容已经结束了。
服务器端返回一个响应码,指示这次请求的状态,响应的形式是这样的:
1 | 200 OK |
然后是一个换行,接下来有效载荷(payload),也就是 www.baiud.com 的HTML内容。服务器不会关闭连接,因为客户端请求保持连接,服务器端会保持连接打开,以供之后的请求重用。
如果浏览器发送的HTTP头部包含了足够多的信息(例如包含了 Etag 头部),以至于服务器可以判断出,浏览器缓存的文件版本自从上次获取之后没有再更改过,服务器可能会返回这样的响应:
1 | 304 Not Modified |
这个响应没有有效载荷,浏览器会从自己的缓存中取出想要的内容。
在解析完 HTML 之后,浏览器和客户端会重复上面的过程,直到HTML页面引入的所有资源(图片,CSS,favicon.ico等等)全部都获取完毕,区别只是头部的 GET / HTTP/1.1 会变成 GET /$(相对www.baidu.com的URL) HTTP/1.1 。
如果 HTML 引入了 www.baidu.com 域名之外的资源,浏览器会回到上面解析域名那一步,按照下面的步骤往下一步一步执行,请求中的 Host 头部会变成另外的域名。
HTTPD(HTTP Daemon)在服务器端处理请求/响应。最常见的 HTTPD 有 Linux 上常用的 Apache 和 nginx,以及 Windows 上的 IIS。
HTTPD 接收请求
服务器把请求拆分为以下几个参数:
服务器验证其上已经配置了 baidu.com 的虚拟主机
服务器验证 baidu.com 接受 GET 方法
服务器验证该用户可以使用 GET 方法(根据 IP 地址,身份信息等)
如果服务器安装了 URL 重写模块(例如 Apache 的 mod_rewrite 和 IIS 的 URL Rewrite),服务器会尝试匹配重写规则,如果匹配上的话,服务器会按照规则重写这个请求
服务器根据请求信息获取相应的响应内容,这种情况下由于访问路径是 “/“ ,会访问首页文件(你可以重写这个规则,但是这个是最常用的)。
服务器会使用指定的处理程序分析处理这个文件,假如 Baidu 使用 PHP,服务器会使用 PHP 解析 index 文件,并捕获输出,把 PHP 的输出结果返回给请求者。
当服务器提供了资源之后(HTML,CSS,JS,图片等),浏览器会执行下面的操作:
浏览器的功能是从服务器上取回你想要的资源,然后展示在浏览器窗口当中。资源通常是 HTML 文件,也可能是 PDF,图片,或者其他类型的内容。资源的位置通过用户提供的 URI(Uniform Resource Identifier) 来确定。
浏览器解释和展示 HTML 文件的方法,在 HTML 和 CSS 的标准中有详细介绍。这些标准由 Web 标准组织 W3C(World Wide Web Consortium) 维护。
不同浏览器的用户界面大都十分接近,有很多共同的 UI 元素:
组成浏览器的组件有:
用户界面 用户界面包含了地址栏,前进后退按钮,书签菜单等等,除了请求页面之外所有你看到的内容都是用户界面的一部分
浏览器引擎 浏览器引擎负责让 UI 和渲染引擎协调工作
渲染引擎 渲染引擎负责展示请求内容。如果请求的内容是 HTML,渲染引擎会解析 HTML 和 CSS,然后将内容展示在屏幕上
网络组件 网络组件负责网络调用,例如 HTTP 请求等,使用一个平台无关接口,下层是针对不同平台的具体实现
UI后端 UI 后端用于绘制基本 UI 组件,例如下拉列表框和窗口。UI 后端暴露一个统一的平台无关的接口,下层使用操作系统的 UI 方法实现
Javascript 引擎 Javascript 引擎用于解析和执行 Javascript 代码
数据存储 数据存储组件是一个持久层。浏览器可能需要在本地存储各种各样的数据,例如 Cookie 等。浏览器也需要支持诸如 localStorage,IndexedDB,WebSQL 和 FileSystem 之类的存储机制
浏览器渲染引擎从网络层取得请求的文档,一般情况下文档会分成8kB大小的分块传输。
HTML 解析器的主要工作是对 HTML 文档进行解析,生成解析树。
解析树是以 DOM 元素以及属性为节点的树。DOM是文档对象模型(Document Object Model)的缩写,它是 HTML 文档的对象表示,同时也是 HTML 元素面向外部(如Javascript)的接口。树的根部是”Document”对象。整个 DOM 和 HTML 文档几乎是一对一的关系。
HTML不能使用常见的自顶向下或自底向上方法来进行分析。主要原因有以下几点:
语言本身的“宽容”特性
HTML 本身可能是残缺的,对于常见的残缺,浏览器需要有传统的容错机制来支持它们
解析过程需要反复。对于其他语言来说,源码不会在解析过程中发生变化,但是对于 HTML 来说,动态代码,例如脚本元素中包含的 document.write() 方法会在源码中添加内容,也就是说,解析过程实际上会改变输入的内容
由于不能使用常用的解析技术,浏览器创造了专门用于解析 HTML 的解析器。解析算法在 HTML5 标准规范中有详细介绍,算法主要包含了两个阶段:标记化(tokenization)和树的构建。
浏览器开始加载网页的外部资源(CSS,图像,Javascript 文件等)。
此时浏览器把文档标记为可交互的(interactive),浏览器开始解析处于“推迟(deferred)”模式的脚本,也就是那些需要在文档解析完毕之后再执行的脚本。之后文档的状态会变为“完成(complete)”,浏览器会触发“加载(load)”事件。
注意解析 HTML 网页时永远不会出现“无效语法(Invalid Syntax)”错误,浏览器会修复所有错误内容,然后继续解析。
<style> 标签包含的内容以及 style 属性的值通过遍历DOM节点树创建一个“Frame 树”或“渲染树”,并计算每个节点的各个CSS样式值
通过累加子节点的宽度,该节点的水平内边距(padding)、边框(border)和外边距(margin),自底向上的计算”Frame 树”中每个节点的首选(preferred)宽度
通过自顶向下的给每个节点的子节点分配可行宽度,计算每个节点的实际宽度
通过应用文字折行、累加子节点的高度和此节点的内边距(padding)、边框(border)和外边距(margin),自底向上的计算每个节点的高度
使用上面的计算结果构建每个节点的坐标
当存在元素使用 floated,位置有 absolutely 或 relatively 属性的时候,会有更多复杂的计算,详见http://dev.w3.org/csswg/css2/ 和 http://www.w3.org/Style/CSS/current-work
创建layer(层)来表示页面中的哪些部分可以成组的被绘制,而不用被重新栅格化处理。每个帧对象都被分配给一个层
页面上的每个层都被分配了纹理
每个层的帧对象都会被遍历,计算机执行绘图命令绘制各个层,此过程可能由CPU执行栅格化处理,或者直接通过D2D/SkiaGL在GPU上绘制
上面所有步骤都可能利用到最近一次页面渲染时计算出来的各个值,这样可以减少不少计算量
计算出各个层的最终位置,一组命令由 Direct3D/OpenGL发出,GPU命令缓冲区清空,命令传至GPU并异步渲染,帧被送到Window Server。
渲染结束后,浏览器根据某些时间机制运行 JavaScript 代码或与用户交互(在搜索栏输入关键字获得搜索建议)。类似 Flash 和 Java 的插件也会运行,尽管 Baidu 主页里没有。这些脚本可以触发网络请求,也可能改变网页的内容和布局,产生又一轮渲染与绘制。