Scrapy爬虫框架教程(一)– Scrapy入门
Scrapy爬虫框架教程(二)– 爬取豆瓣电影TOP250
Scrapy爬虫框架教程(三)– 调试(Debugging)Spiders
前言
前一段时间工作太忙一直没有时间继续更新这个教程,最近离职了趁着这段时间充裕赶紧多写点东西。之前我们已经简单了解了对普通网页的抓取,今天我就给大家讲一讲怎么去抓取采用Ajax异步加的网站。
工具和环境
- 语言:python 2.7
- IDE: Pycharm
- 浏览器:Chrome
- 爬虫框架:Scrapy 1.3.3
什么是AJAX?
AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术。
AJAX = 异步 JavaScript和XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
两个Chrome插件
Toggle JavaScript
这个插件可以帮助我们快速直观地检测网页里哪些信息是通过AJAX异步加载而来的,具体怎么用,下面会详细讲解。
chrome商店下载地址:https://chrome.google.com/webstore/detail/toggle-javascript/cidlcjdalomndpeagkjpnefhljffbnlo?utm_source=chrome-app-launcher-info-dialog(Ps:打不的小伙伴自行百度搜索国内提供chrome插件下载的网站离线安装)
JSON-handle
这个插件可以帮我们格式化Json串,从而让我们以一个更友好的方式查看Json内的信息。
chrome商店下载地址:https://chrome.google.com/webstore/detail/json-handle/iahnhfdhidomcpggpaimmmahffihkfnj(Ps:打不的小伙伴自行百度搜索国内提供chrome插件下载的网站离线安装)
分析过程
分析页面是否采用AJAX
上次我们拿了豆瓣当做例子,刚好我发现了豆瓣有AJAX异步加载的页面,这次我们就不换了,还拿豆瓣做例子。(逃
首先我们打开豆瓣电影分类排行榜 - 动作片栏目。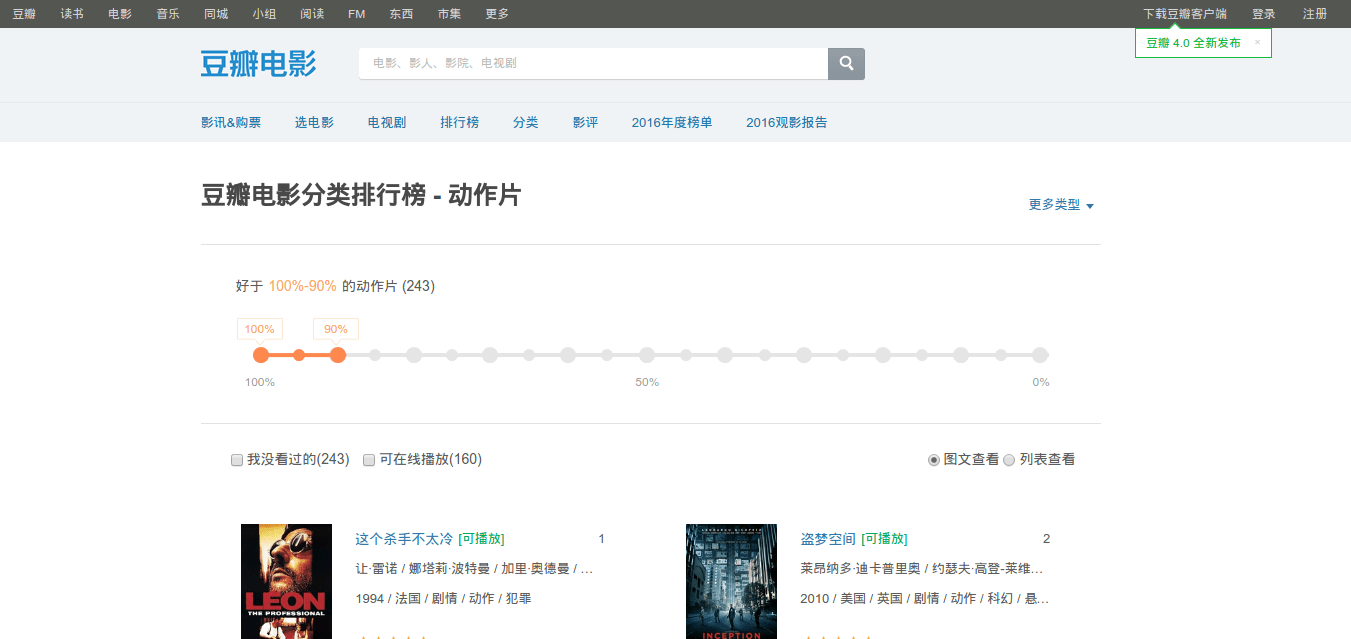
打开过后你有没有发现什么不一样的地方呢?如果你的网速慢你会发现下面的电影信息是在网页别的部分出现后才慢慢出现的,试着把界面往下滑会不断有新的电影信息更新出来。
遇到这种情况初步就可以认定这个页面是采用AJAX异步加载的,你也可以通过右键查看网页源码来鉴别。比如说你右键查看源码ctrl+f搜索这个杀手不太冷这几个字,你会发现源码里没有。
上面的方法虽然能用,但是总感觉有点笨。还记得上面推荐的那个chrome插件Toggle JavaScript吗?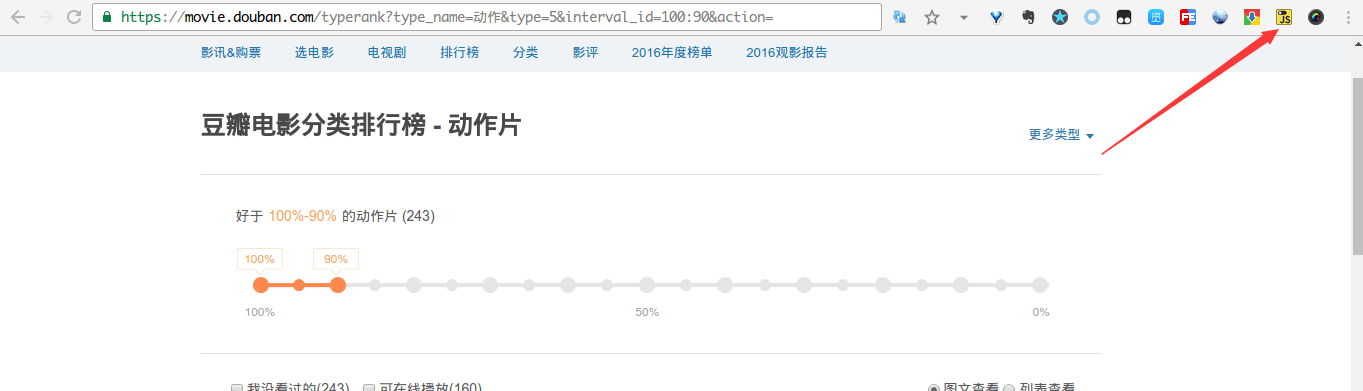
安好这个插件它就会出现在chrome浏览器的右边,试着轻轻点一下。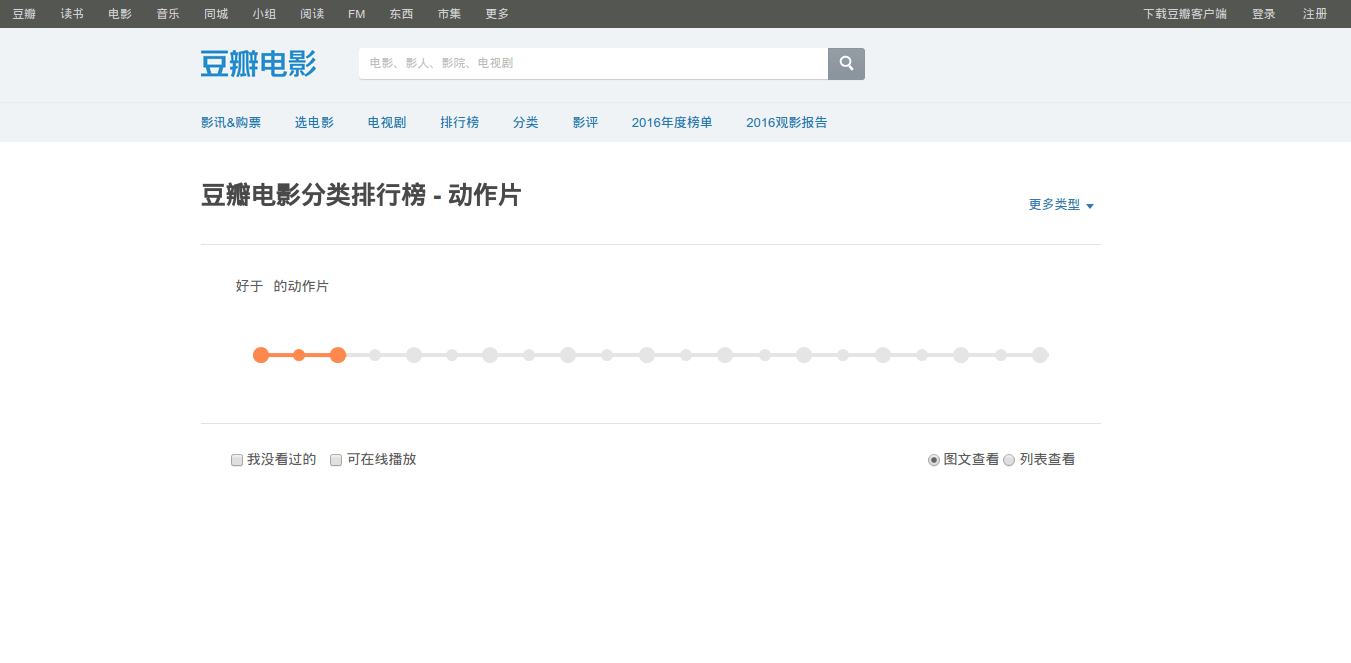
我的天呐!这么神奇吗?!刚才的电影信息都不见了!还记得AJAX的介绍吗?AJAX = 异步 JavaScript和XML。当我们点击了插件就代表这个我们封禁了JavaScript,这个页面里的JavaScript代码无法执行,那么通过AJAX异步加载而来的信息当然就无法出现了。通过这种方法我们能快速精确地知道哪些信息是异步加载而来的。
如何抓取AJAX异步加载页面
对于这种网页我们一般会采用两种方法:
- 通过抓包找到AJAX异步加载的请求地址;
- 通过使用PhantomJS等无头浏览器执行JS代码后再对网页进行抓取。
通常情况下我会采用第一种方法,因为使用无头浏览器会大大降低抓取效率,而且第一种方法得到的数据格式往往以Json为主,非常干净。在这里我只讲解第一种方法,第二种方法作为爬虫的终极武器我会在后续的教程中进行讲解。
回到我们需要抓取的页面,还记得我说过页面的一个细节吗,下拉更新。进入页面后我们按F12打开chrome浏览器的开发者工具选择Network,然后实现一次下拉更新。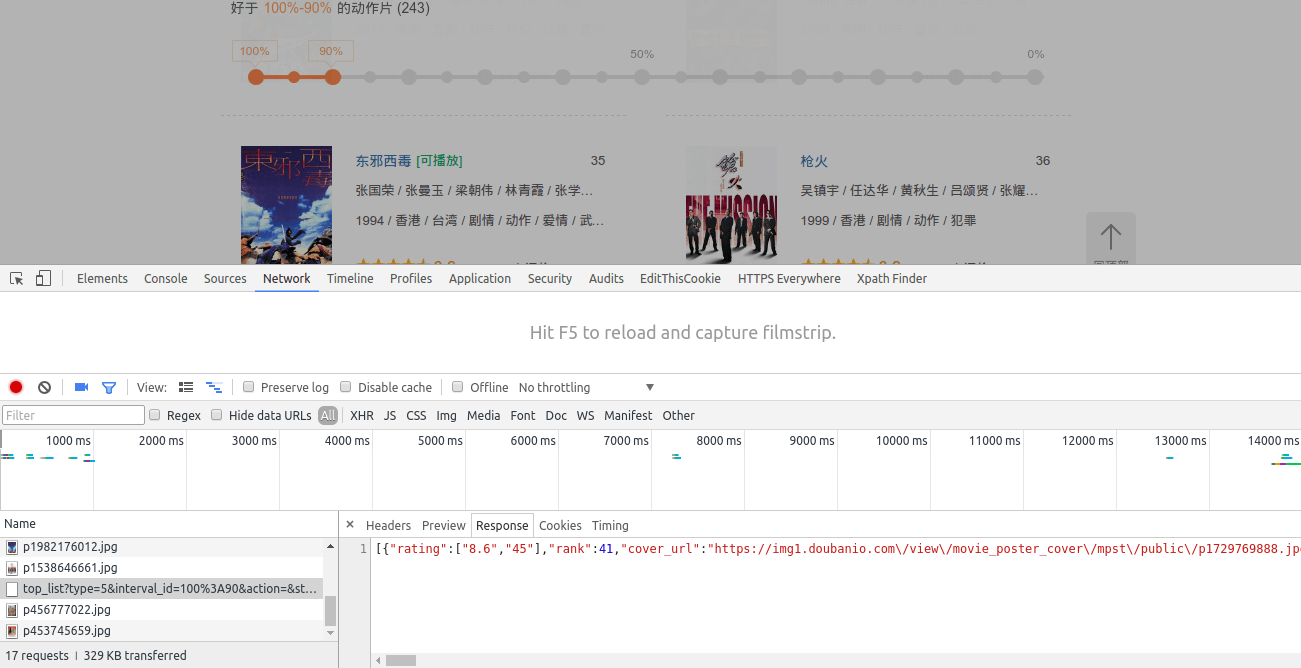
你会在Network里发现一个Response为Json格式的请求,仔细看看Json里的内容你会明白这些都是网页上显示的电影信息。右键该请求地址选择Open Link in New Tab,如果你装了JSON-handle插件你会以下面这种更友好的方式查看这个Json串。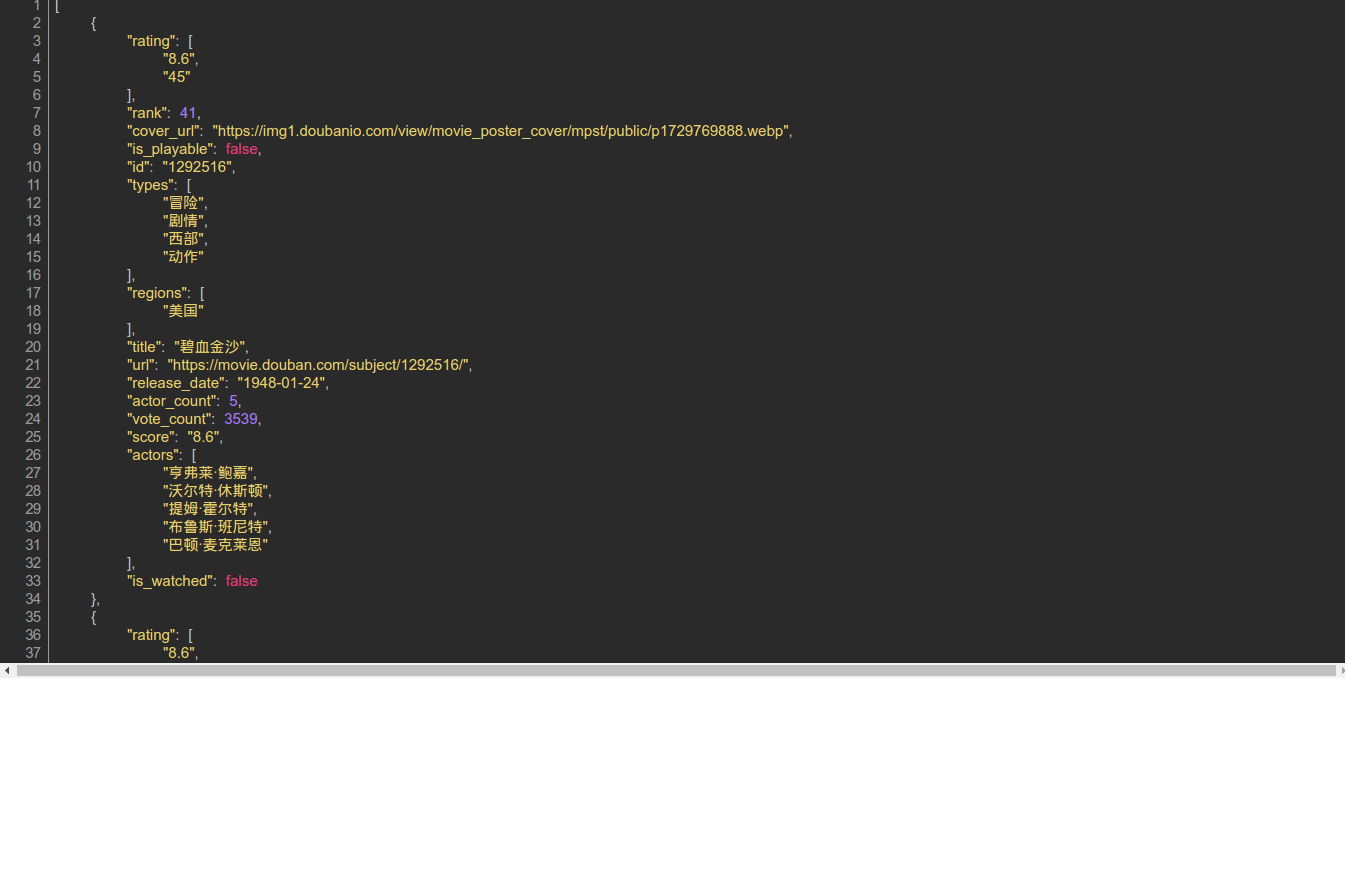
接着再让我们看一该请求的Header信息。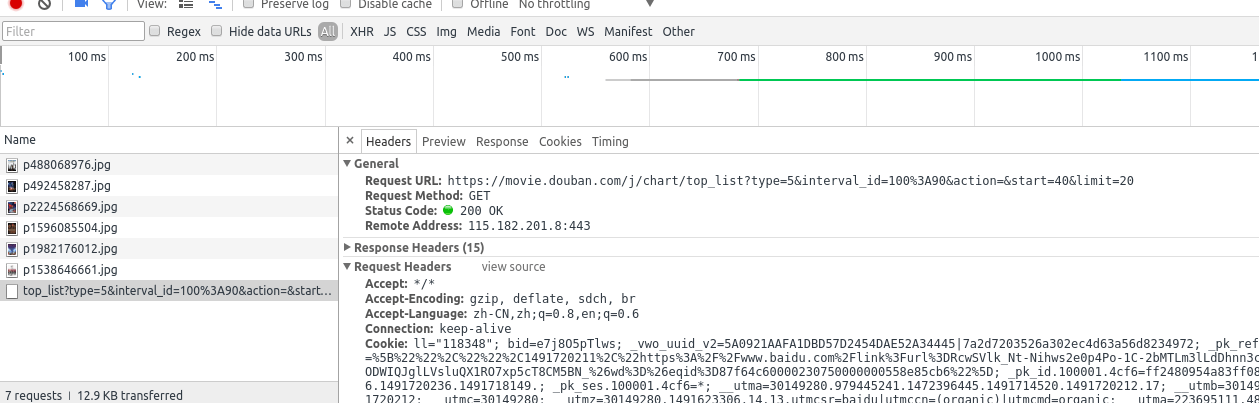
首先我们可以看出这是一个get请求,多看几个下拉请求的地址后你会发现地中的start=xxx在不断变化,每次增加20。所以我们只用更改这个参数就可以实现翻页不断获取新数据(修改其他的参数也会有不同的效果,这里就不一一细说了,留给大家慢慢地探索)。
spider代码如下:
1 | # -*- coding: utf-8 -*- |
在Scrapy工程文件的spiders里写好爬虫文件后在settings.py所在的目录下打开终端运行以下代码就能输出相应的电影数据。
1 | scrapy crawl douban_ajax -o douban_movie.csv |
结尾
整片文章主要以介绍思路为主,抓取的站点也只是做示范内容并不重要。授之以鱼不如授之以渔,希望大家可以从这篇教程里学到解决问题的方法与思路。: )

