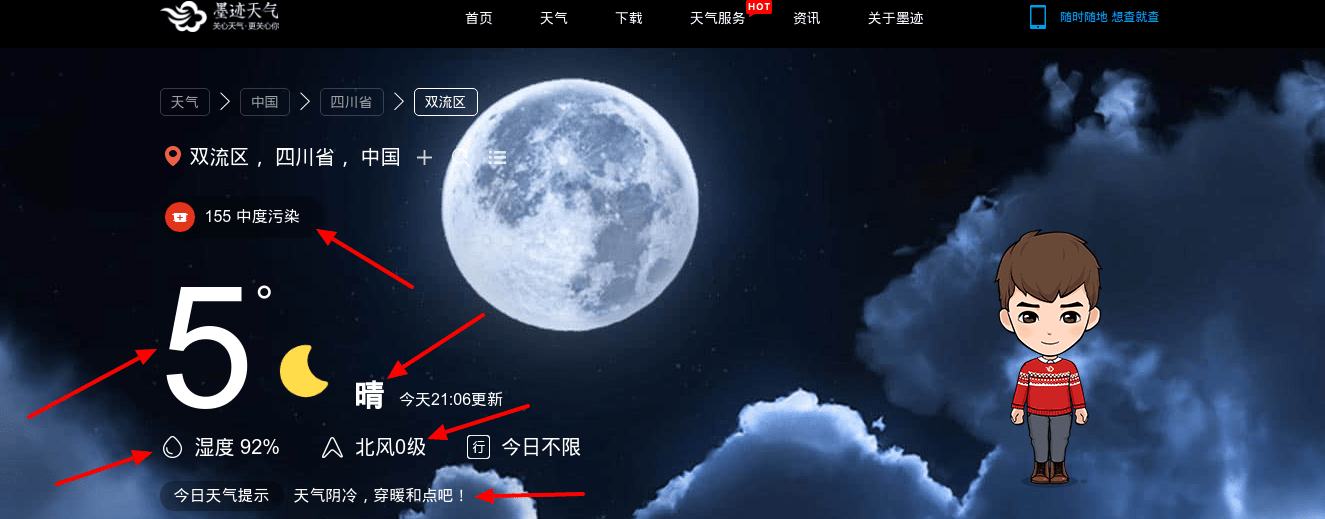
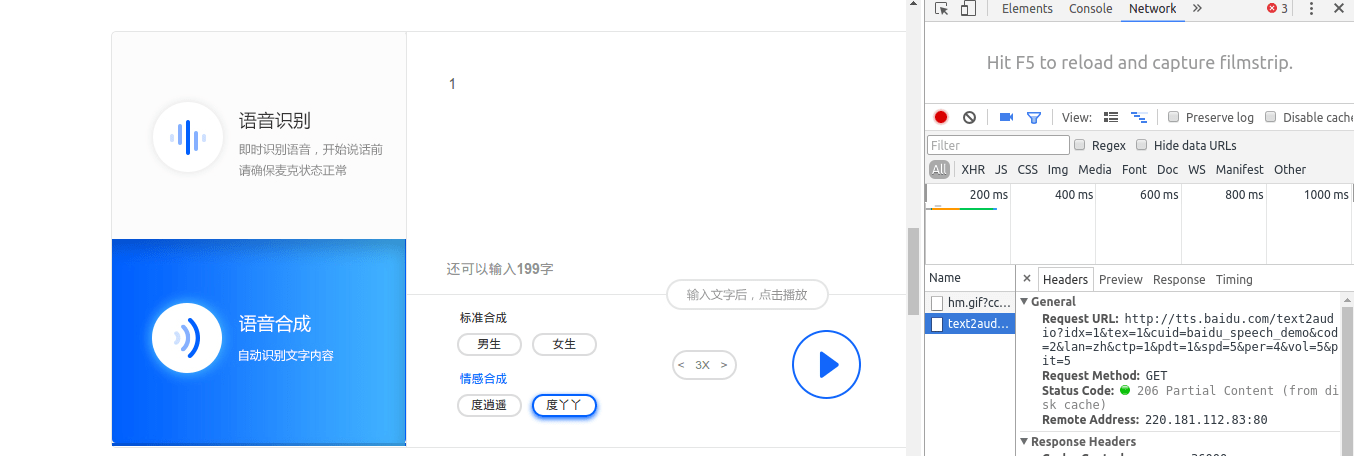
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
import os
import re
import time
import requests
from datetime import datetime, timedelta
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
def numtozh(num):
num_dict = {1: '一', 2: '二', 3: '三', 4: '四', 5: '五', 6: '六', 7: '七',
8: '八', 9: '九', 0: '零'}
num = int(num)
if 100 <= num < 1000:
b_num = num // 100
s_num = (num-b_num*100) // 10
g_num = (num-b_num*100) % 10
if g_num == 0 and s_num == 0:
num = '%s百' % (num_dict[b_num])
elif s_num == 0:
num = '%s百%s%s' % (num_dict[b_num], num_dict.get(s_num, ''), num_dict.get(g_num, ''))
elif g_num == 0:
num = '%s百%s十' % (num_dict[b_num], num_dict.get(s_num, ''))
else:
num = '%s百%s十%s' % (num_dict[b_num], num_dict.get(s_num, ''), num_dict.get(g_num, ''))
elif 10 <= num < 100:
s_num = num // 10
g_num = (num-s_num*10) % 10
if g_num == 0:
g_num = ''
num = '%s十%s' % (num_dict[s_num], num_dict.get(g_num, ''))
elif 0 <= num < 10:
g_num = num
num = '%s' % (num_dict[g_num])
elif -10 < num < 0:
g_num = -num
num = '零下%s' % (num_dict[g_num])
elif -100 < num <= -10:
num = -num
s_num = num // 10
g_num = (num-s_num*10) % 10
if g_num == 0:
g_num = ''
num = '零下%s十%s' % (num_dict[s_num], num_dict.get(g_num, ''))
return num
def get_weather():
res = requests.get('http://tianqi.moji.com/', headers=headers)
soup = BeautifulSoup(res.text, "html.parser")
temp = soup.find('div', attrs={'class': 'wea_weather clearfix'}).em.getText()
temp = numtozh(int(temp))
weather = soup.find('div', attrs={'class': 'wea_weather clearfix'}).b.getText()
sd = soup.find('div', attrs={'class': 'wea_about clearfix'}).span.getText()
sd_num = re.search(r'\d+', sd).group()
sd_num_zh = numtozh(int(sd_num))
sd = sd.replace(sd_num, sd_num_zh)
wind = soup.find('div', attrs={'class': 'wea_about clearfix'}).em.getText()
aqi = soup.find('div', attrs={'class': 'wea_alert clearfix'}).em.getText()
aqi_num = re.search(r'\d+', aqi).group()
aqi_num_zh = numtozh(int(aqi_num))
aqi = aqi.replace(aqi_num, aqi_num_zh).replace(' ', ',空气质量')
info = soup.find('div', attrs={'class': 'wea_tips clearfix'}).em.getText()
sd = sd.replace(' ', '百分之').replace('%', '')
aqi = 'aqi' + aqi
info = info.replace(',', ',')
today = datetime.now().date().strftime('%Y年%m月%d日')
text = '早上好!今天是%s,天气%s,温度%s摄氏度,%s,%s,%s,%s' % \
(today, weather, temp, sd, wind, aqi, info)
return text
def text2voice(text):
url = 'http://tts.baidu.com/text2audio?idx=1&tex={0}&cuid=baidu_speech_' \
'demo&cod=2&lan=zh&ctp=1&pdt=1&spd=4&per=4&vol=5&pit=5'.format(text)
os.system('mplayer "%s"' % url)
def main():
text = get_weather()
print(text)
mp3path2 = os.path.join(os.path.dirname(__file__), '2.mp3')
os.system('mplayer %s' % mp3path2)
text2voice(text)
if __name__ == '__main__':
main()
|